What Is AI/ML and Why I’m Learning It
- Series: Mastering AI/ML from First Principles
- Phase: Orientation
- Blog Number: 01
Why AI/ML matters now
Artificial Intelligence is no longer a niche research topic. It now shapes search, recommendations, forecasting, fraud detection, language tools, image systems, and a growing share of modern software. Most people are already using AI-powered systems long before they understand what those systems are actually doing. Recent progress in data, compute, and learning methods has made AI far more practical and visible at scale.
That is exactly why I want to study this field properly.
I do not want AI to remain a collection of black-box tools, polished demos, and vendor language that I can use without really understanding. I want to know what these systems are, what machine learning is actually doing, where deep learning fits, and what mathematical ideas make all of this work.
This series is my attempt to close that gap in a disciplined way.
Why I’m learning this
I have spent much of my career working with systems, infrastructure, automation, and architecture. That background taught me how to think about scale, reliability, orchestration, and platform design. But AI/ML introduces a different kind of system behavior.
Traditional software executes rules that humans explicitly define. Machine learning systems, in contrast, learn patterns from data and use those patterns to make predictions or decisions. That shift matters. IBM defines machine learning as a subset of AI focused on algorithms that learn patterns from training data and make inferences about new data, which is a cleaner way to say what I’m trying to understand here.
I do not want to stop at deploying intelligent systems. I want to understand how they work from first principles. I want to understand the math, the assumptions, the tradeoffs, and the failure modes.
This is not a casual exploration for me. It is a serious learning journey.
What AI, ML, and Deep Learning actually mean
Artificial Intelligence
Artificial Intelligence is the broad field of building systems that perform tasks we associate with intelligence, such as problem solving, language use, decision making, and perception.
Machine Learning
Machine Learning is a subfield of AI where systems learn patterns from data instead of relying only on hand-written rules. In practice, it is the main approach behind much of modern AI.
Deep Learning
Deep Learning is a subfield of machine learning built around multilayer neural networks. It has been especially successful in vision, speech, language, and generative systems.
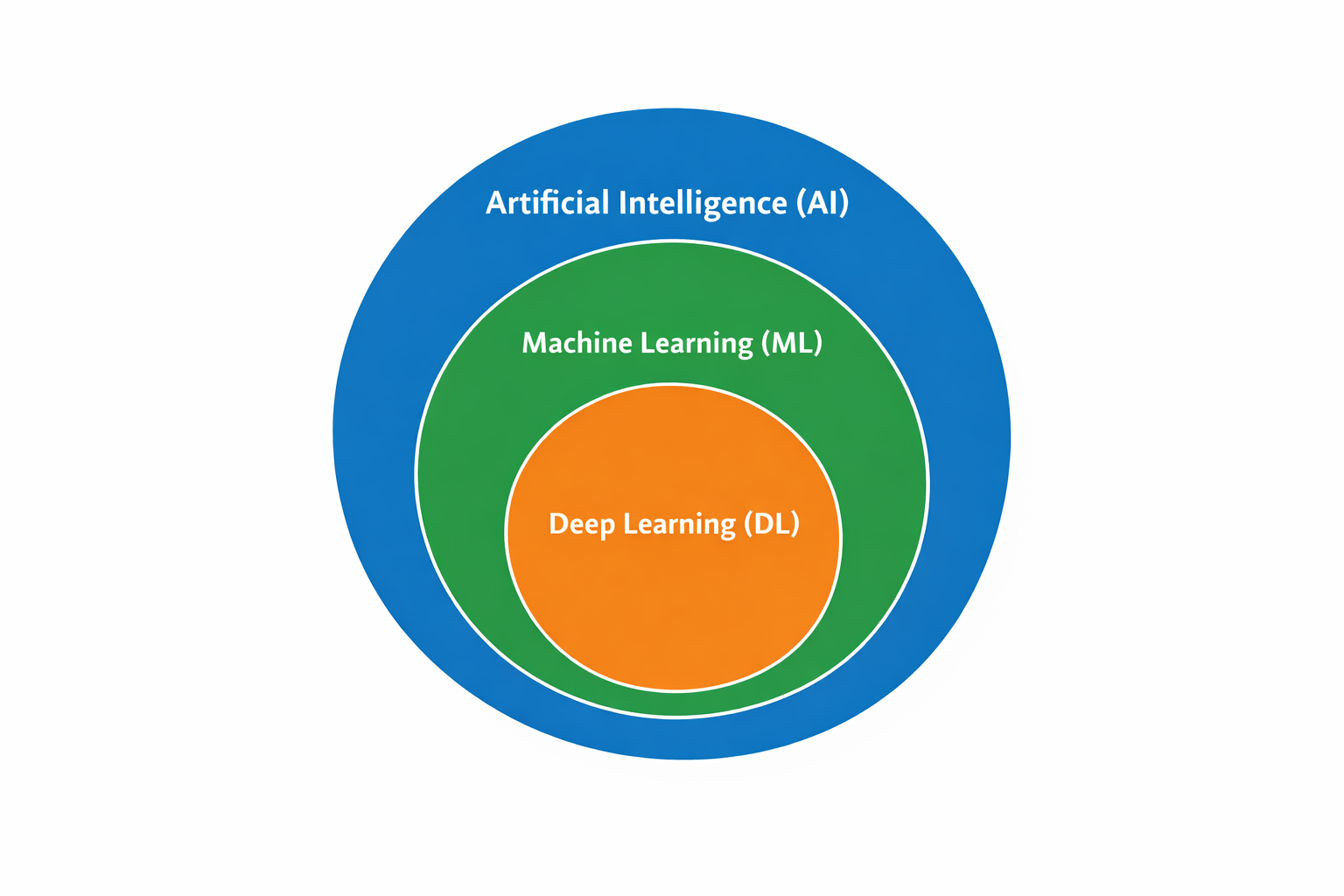
Relationship between Artificial Intelligence, Machine Learning, and Deep Learning
AI vs ML vs Deep Learning
Term | What it means | Typical examples |
AI | Broad field of building intelligent systems | Search, planning, reasoning systems, language systems |
ML | Subfield of AI that learns patterns from data | Spam filtering, price prediction, recommendations |
Deep Learning | Subfield of ML using multilayer neural networks | Image recognition, speech models, LLMs |
Why these terms get confused
These terms are often confused because most high-visibility AI products today are powered by machine learning, and many of the biggest recent breakthroughs come from deep learning. So people hear “AI,” “ML,” and “deep learning” used around the same systems and assume they are interchangeable.
They are not. The cleaner hierarchy is:
- AI is the broad field
- ML is one major approach within AI
- DL is one major approach within ML
That distinction matters because it keeps the conversation precise.
What AI is not
- AI is not magic.
- It is not automatic truth.
- It is not always human-like reasoning.
- It is not always understanding in the way people casually assume.
A lot of AI systems are doing pattern recognition under uncertainty. They can be useful, impressive, and valuable while still being wrong, biased, brittle, or overconfident. That is one of the main reasons I want to learn this field carefully instead of treating it like a black box.
Traditional programming vs machine learning
The clearest mental shift for me is this: In traditional programming, I write rules.
In machine learning, I give a model data and a training process so it can learn patterns.
A rule-based spam system might say:
If the email contains "lottery", mark it as spam.
If the sender matches a blocked domain, reject it.That works for narrow cases, but it breaks down quickly. Real-world data is noisy, changing, and full of exceptions.
In machine learning, I can instead provide many examples of spam and non-spam emails. The model learns statistical patterns that help it classify new emails.
So the shift is not from programming to no programming.
It is from explicit rule-writing to learning from examples.
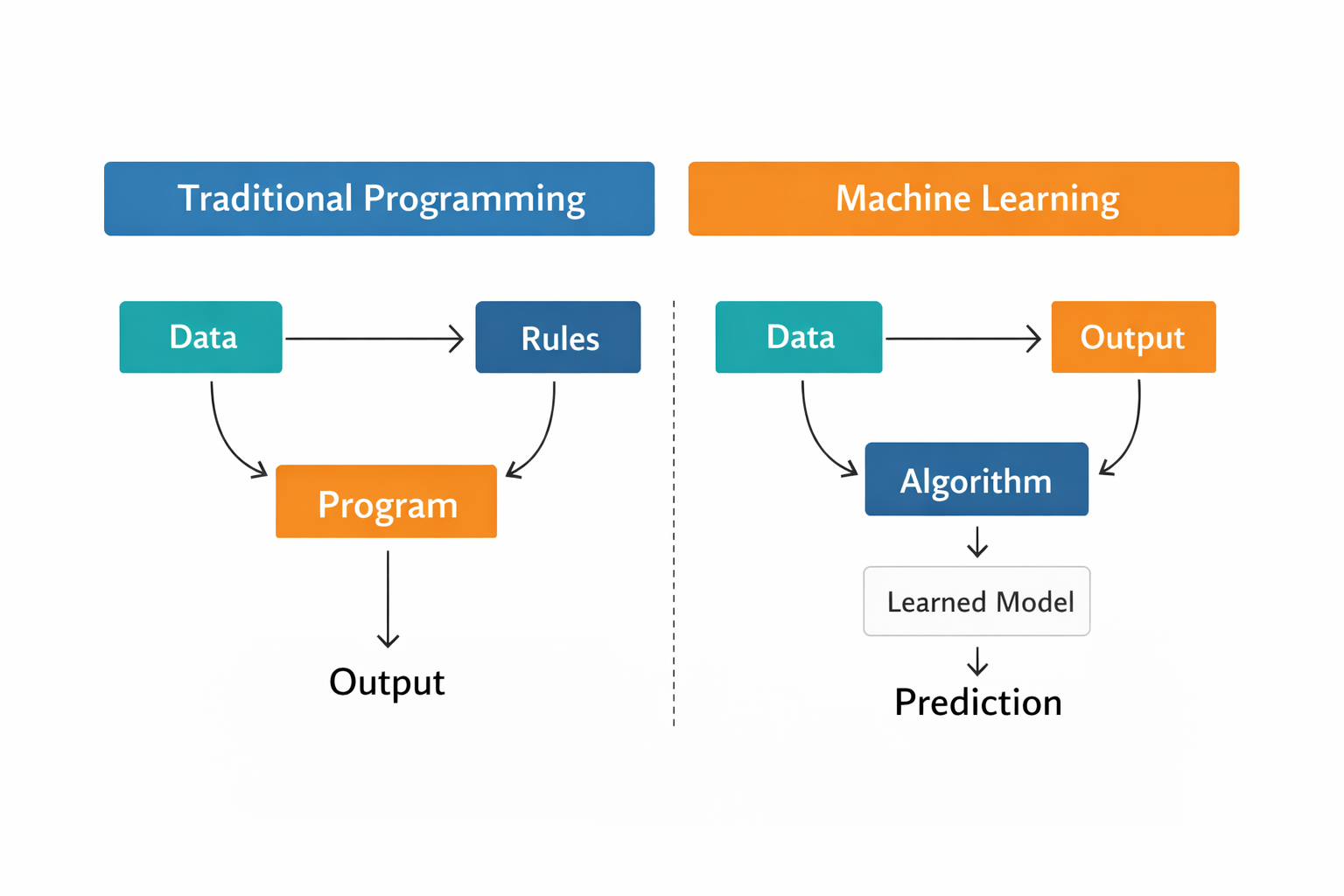
Traditional programming relies on explicit rules, while machine learning learns patterns from data.
A simple conceptual example
Suppose I want to predict house prices.
In a rule-based system, I might write rules like:
- larger homes usually cost more
- more bedrooms usually increase price
- better locations usually increase price
That sounds fine until real-world factors start interacting. Area, age, neighborhood, renovation quality, transit access, and market conditions all matter together.
With machine learning, I can provide data like this:
Area | Bedrooms | Location Score | Price |
1200 | 2 | 6 | 350000 |
1800 | 3 | 8 | 540000 |
2200 | 4 | 9 | 720000 |
The model tries to learn a relationship from inputs to outputs. Stanford’s ML notes use this same house-price framing because it captures the basic supervised learning setup cleanly.
That does not mean the model “understands” housing the way a person does. It means it identifies patterns in the data that help it make predictions on new examples.
A short history of how we got here
AI did not suddenly appear in the last few years.
The early decades of AI were shaped by symbolic methods, logic, and search. The 1980s saw the rise of expert systems, which encoded domain knowledge as rules. Later, as data and computing power improved, statistical learning became far more influential. Then came the 2012 AlexNet/ImageNet result, which showed how powerful deep neural networks could be on perception tasks. The 2020s pushed this further with foundation models and generative AI systems that operate across language, vision, and multimodal tasks.
So AI is not new. But recent advances have made it dramatically more useful, scalable, and visible.
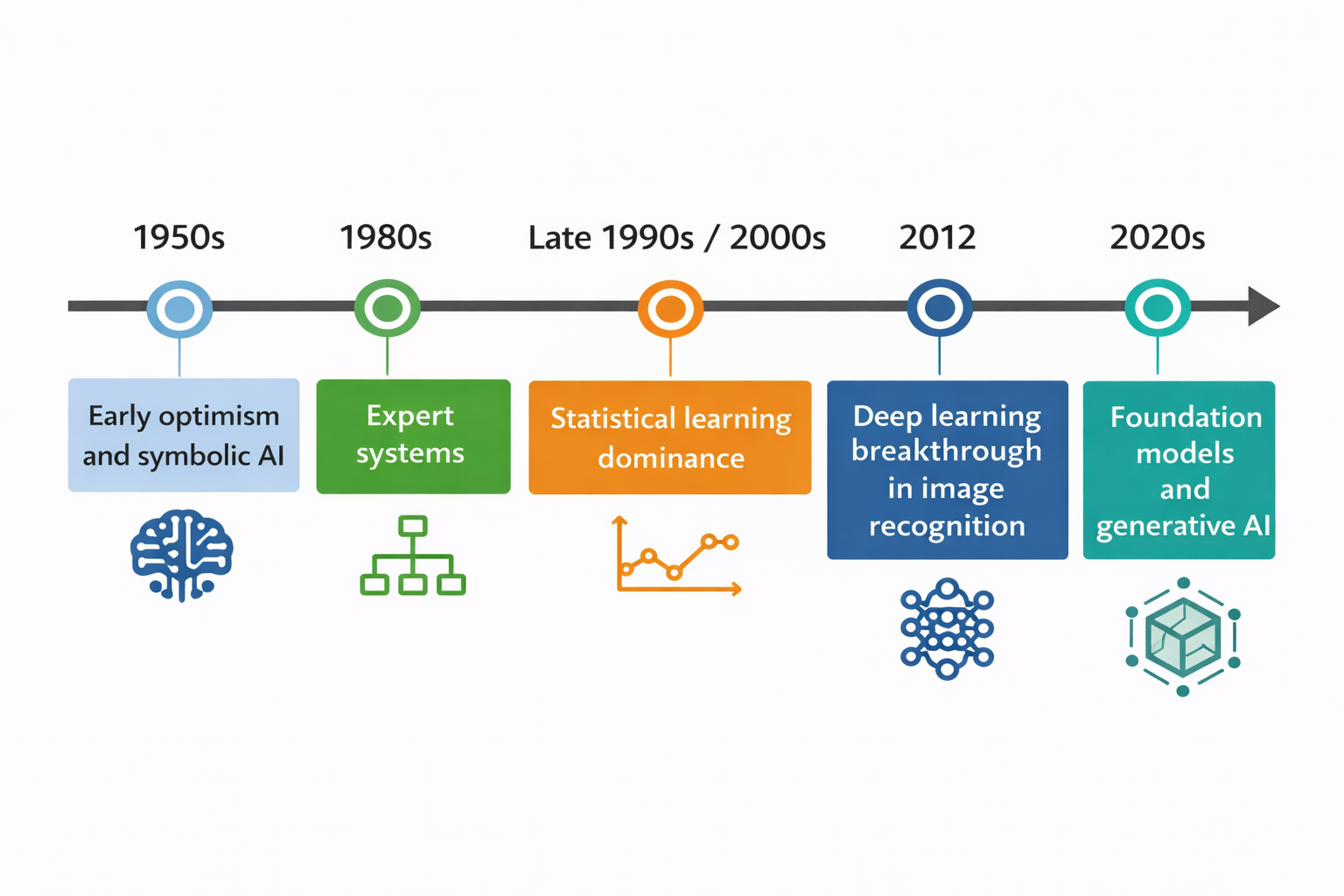
Key milestones in the evolution of AI—from symbolic systems to modern generative models
What machine learning is doing mathematically
At a high level, machine learning is about learning a mapping from inputs to outputs:
$$
y = f(x)
$$
Where:
- x is the input
- y is the output
- f is the function the model is trying to learn
For a housing example:
$$
\text{Price} = f(\text{area}, \text{bedrooms}, \text{location}, \text{age}, \dots)
$$
Or in ML terms:
$$
\text{Price} = f(\text{features})
$$
The goal of training is to find a useful version of that function from data and then apply it to new examples. That framing is standard in introductory ML and shows up clearly in Stanford’s lecture notes.
This is where the real questions begin:
- What form should that function take?
- How do we measure error?
- How do we improve the model?
- How do we know it generalizes?
That is the part I want to understand deeply.
Tiny Python example
This is not “real AI” in the broad sense. It is just the smallest possible example of a system learning a relationship from data.
from sklearn.linear_model import LinearRegression
import numpy as np
# Training data: house size in square feet
X = np.array([[500], [1000], [1500], [2000]])
# Target values: corresponding prices
y = np.array([100, 200, 300, 400])
# Create the model
model = LinearRegression()
# Train the model
model.fit(X, y)
# Predict the price for a new house size
prediction = model.predict([[1200]])
print("Predicted price:", prediction[0])What happened here?
- I gave the model example inputs and outputs
- The model learned a simple relationship
- It used that relationship to predict a new value
Real ML is far messier than this. But this tiny example captures the core idea.
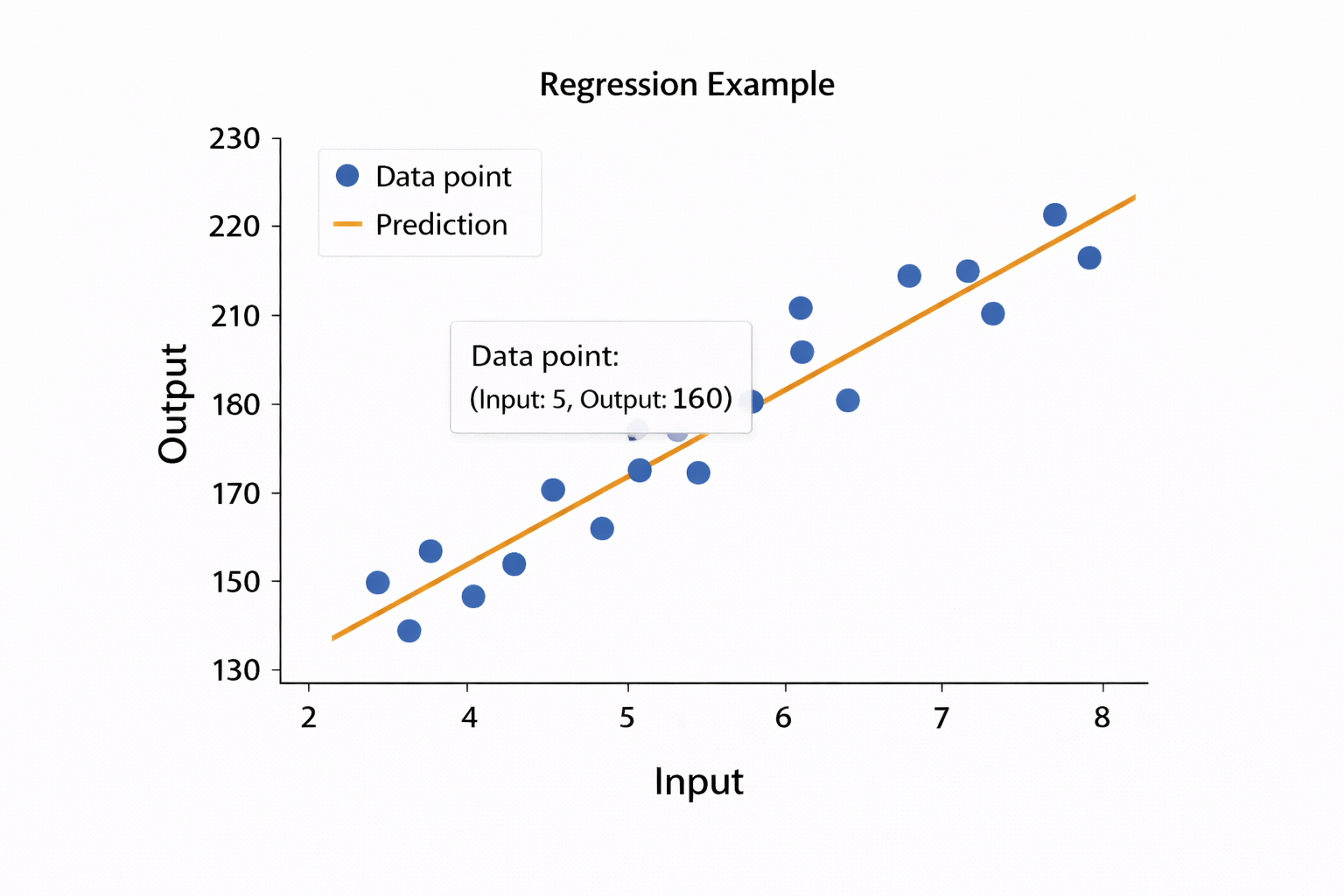
A simple example of learning a relationship from data using linear regression
What still confuses me
I do not want this series to sound artificially polished. I am starting this journey with real curiosity, which means being honest about what I do not yet fully understand.
The questions still pulling at me are:
- What does a model actually learn internally?
- What does “training” mean beyond the surface definition?
- Why do some models generalize while others overfit?
- How do loss functions, gradients, and optimization work together?
- How do we know a model is learning signal instead of memorizing noise?
- What changes when the data becomes incomplete, messy, biased, or unstable?
These are not side questions. They are the core of the journey ahead.
Who this series is for
I am writing this series for people who want depth rather than shortcuts.
This series is for:
- engineers who want to understand AI/ML from the ground up
- learners who are tired of “import model, fit model, done”
- practitioners who want intuition before jargon
- people who want to connect math, code, and real-world problem solving
This is not a hype series.
It is not a surface-level tool tutorial series.
It is a structured path from intuition to mathematics to implementation to real systems.
Roadmap for the series
Phase 1 — Math foundations
Numbers, variables, and why ML needs math
Functions: the language of ML
Graphs and visualizing functions
Vectors: representing data in ML
Vector operations: dot product, length, distance
Matrices: representing datasets and transformations
Matrix multiplication and why it matters
Derivatives: understanding change
Gradients: direction of learning
Optimization: how models learn
Phase 2 — Probability and statistics
What probability means in ML
Random variables and distributions
Mean, variance, and standard deviation
Common distributions in AI/ML
Conditional probability and Bayes’ theorem
Sampling and statistical inference
Bias, variance, and noise
Correlation vs causation
Likelihood and intuition behind estimation
From statistics to learning
Phase 3 — Core machine learning
What a machine learning model actually is
Supervised vs unsupervised learning
Linear regression from intuition to implementation
Loss functions and how models measure error
Gradient descent step by step
Logistic regression for classification
k-nearest neighbors
Decision trees
Model evaluation: accuracy, precision, recall, F1
Train/validation/test splits and cross-validation
Milestone Project 1
A real beginner-friendly end-to-end project:
- problem framing
- preprocessing
- model building
- evaluation
- reflection
Phase 4 — Practical machine learning
Working with real tabular datasets
Missing values and imperfect data
Categorical variables and encoding
Feature scaling and normalization
Feature engineering
Pipelines and reproducible preprocessing
Baseline models vs improved models
Hyperparameter tuning
Error analysis
Interpreting model behavior
Phase 5 — Advanced machine learning
Bias-variance tradeoff in practice
Ensemble learning intuition
Random forests
Gradient boosting
Support vector machines
Dimensionality reduction and PCA
Clustering and unsupervised structure
Model selection strategies
Milestone Project 2
A portfolio-grade project using messy real-world data.
Phase 6 — Deep learning
From perceptrons to neural networks
Forward propagation
Activation functions
Backpropagation intuition
Training neural networks
Overfitting and regularization
Convolutional neural networks
Sequence models and language intuition
Transformers at a conceptual level
Phase 7 — Real-world ML systems
From notebook to production thinking
Data pipelines and feature pipelines
Model serving basics
Monitoring model performance
Drift, retraining, and lifecycle management
Evaluation in real-world systems
ML system tradeoffs: accuracy, latency, cost, reliability
Building ML responsibly
Key takeaways
- AI is the broad field of building intelligent systems
- Machine learning is the main approach behind much of modern AI
- Deep learning is a powerful subfield of machine learning
- AI is not magic; it is built on data, models, assumptions, and optimization
- The goal is not to memorize tools but to understand how learning systems work
- This series is my structured path from intuition to practice to real systems
References
Books
- Artificial Intelligence: A Modern Approach — Stuart Russell and Peter Norvig
- An Introduction to Statistical Learning — Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani
- The Elements of Statistical Learning — Trevor Hastie, Robert Tibshirani, Jerome Friedman
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow — Aurélien Géron
Courses and notes
Stanford CS229: Machine Learning
Documentation
- IBM AI overview
- IBM Machine Learning overview
- IBM Deep Learning overview
Historical anchor
AlexNet / ImageNet 2012 paper
Closing thought
I am not starting this journey because AI is fashionable.
I am starting it because it is becoming foundational.
I do not want to be someone who can only call a library and get an output. I want to understand what sits beneath the interface: the mathematics, the abstractions, the training process, the limitations, and the engineering tradeoffs.
Right now, I do not know enough.
That is exactly why this series exists.