Hello all, it’s been long since my last blog. In between, I became a father, changed profile, changed location etc., in all a lot happened at personal and professional front.
Coming back to blog, this particular topic was bugging me from last couple of months. In few of my last discussions with customers, it seemed we discussed only one point, that is to decide between fully distributed vs simple installation architecture.More often I have seen people choosing a deployment model not based on careful considerations but based on what the general belief is. This blog tries to shed light on the considerations that should be made before making that decision.
I have met enough customers to safely assume that more than 90% of times a customer will ask us for a distributed deployment irrespective of the size of the environment or total uptime required of the solution. I agree to the fact that it will remove single point of failure thus increasing availability of the overall solution. But the question is should we always choose distributed environment simply because of this point or simply because we can do it?
My point, it depends, and you will be surprised to know how many times I may recommend a simple install over a distributed environment.
Before you think I have gone crazy, let us check the reasons for me saying so.
First point of consideration:
All the management components do not directly affect the running workload. So a downtime of the management components should not have a direct impact to your existing running environment. During that time, you will not be able to manage or do new things in your environment. But this no way is impacting your current SLA for the already running workload. This should be ok in most cases, but if someone has a public cloud and the main management portal goes down obviously it has bigger impact on business and should be avoided.For example, let's consider the following situations.
vCenter goes down – Existing VM’s keep running, no new deployment or management is possible. In case of vRA with vCenter, no new deployment at cloud level is possible as well, but the Cloud portal works.
vRA components go down – Cloud portal is not available, existing workloads keeps running. You can still SSH or RDP to the VM's hosted in cloud. End users operations are not hampered.
Second Point of consideration:
Distributed Environment: Let’s check the implications of a distributed architecture
more closely.
Most of the times, because of the following two reasons this is chosen.
- To remove a single point of failure (increase availability)
- To support a larger environment (if a single node can support say 10000 elements then 2 nodes will support 20000 elements)
A lot of times point two is not applicable. In very few of the instances you would find a customer who exceeds the technical limitation of products.
For example, how many times you have actually seen a single vCenter server to support 1000 ESXi hosts and 15000 powered off VM’s in production? Or for that matter a single vCenter appliance taking care of 10000 powered on VM’s? I am yet to see one. Did you ever see a single ESXi host supporting 1024 VM’s or 4096 vCPU’s deployed in a host? Have you ever seen any customer who is actually touching or nearing to those technical limitation? I doubt.
Besides if you have an environment this big then definitely Distributed way is THE WAY for you.
Coming back to the point, it seems the majority of times the reason a distributed architecture is chosen is to remove a single point of failure and increase availability.
So let’s consider a full distributed environment for a vRA cloud environment and see the effects.
For vRealize Automation components to be full distributed, we need the following:
- Deployed vRA appliance – 2+
- IaaS web server – 2+
- IaaS Manager Service Server – 2+
- IaaS DEM Server – 1+
- Agent Server – 1+
A total of minimum of 8 servers and the following.
- MSSQL Server in HA mode – 2+
If you consider the vCenter environment, then you have the following:
- PSC – 2+
- vCenter – 2+
So a total of 10+ VM’s.
All these components will have Load Balancer in front. So architecturally vCenter environment looks like following:
 |
| Distributed vCenter Deployment Architecture |
Or more precisely:
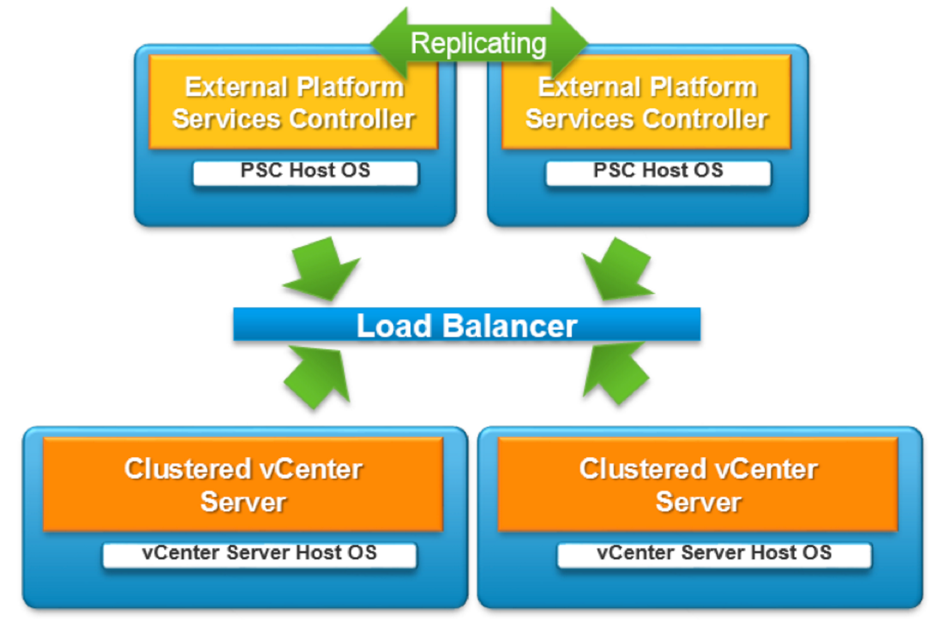 |
| Distributed vCenter Deployment Architecture with Load Balancer |
And the vRA environment should be as given below:
 |
| Distributed vRealize Automation deployment Architecture |
The placement of a Load Balancer has a lot of effect in this environment. Let’s consider a physical load balancer in traditional environment, i.e. somewhere upstream after firewall (at least 2 or 3 hops away from the host on which the VM resides).
Now, let’s check how a normal user request for a VM is handled. A user request comes to the front LB and based on the decision, it goes to the respective vRA appliance. From there it again goes out to LB and comes back to a IaaS web server. Next the request again goes out to LB and based on the decision a Manager server is chosen and finally goes for DEM. The same story applies when the VM creation request goes out to vCenter, it reaches LB for choosing PSC and then vCenter node.
In all, considering all these multiple HOPS to LB think how many extra hops are there simply because of the nature of the deployment. Considering the number of extra hops consider the effect on the overall response time.
Single node deployment:
Now let’s consider the effects of a simple deployment. For our discussion let’s consider the number of supported elements is well within the capability of a single node.
First point, a request will not have to make so many round trips to LB. So obviously response time should be higher than a full distributed environment. So performance is higher.
But the negative effect is now you have a single point of failure. So let’s consider the different availability options to increase the overall uptime?
- The first line of defense is underlying HA with VM monitoring option. Typically, a physical node failure is sensed within 12 seconds and a restart takes place by 15 seconds. For the sake of discussion let’s consider the OS and the application of the VM comes up within 5 minutes. Considering a node failover happens once in a month, total downtime is 5 minutes in a total of 43200 minutes (considering 30-day month). That means you get an uptime of 99.988%. Same goes for VM hung situation or application hung situation. As we are monitoring at the VM level as well.
- Second line of defense is snapshot, if the OS or application gets corrupted we simply revert back to a snapshot. First let’s consider an external database is used, then there is not much change in the original VM, so recovering from a snapshot is sufficient and say it requires 20 seconds. So total uptime is now 99.999%. But if internal database is used, then simply reverting to an earlier snapshot is not enough. In this case we need to revert to an earlier snapshot to recover the OS and then we need to restore the database from the backup (we need to have a regular backup mechanism for the database). This will require more time, say 10 minutes. In that case your uptime is 99.977% (considering internal database and recovery time of 10 minutes).
- Third line of defense is backups. If everything gets corrupted then you need to restore entire appliance from a backup which say take 30 minutes. So in this case you get a 99.931% uptime in a month.
So the choice is based on required uptime. If the business can sustain a 99.931% uptime for management components (at the worst case) and the total supported elements are well within the range, then I will certainly suggest a simple install because of the following reasons:
- Simpler to manage
- Simpler to update
- Will perform better (as compared to full distributed environment)
- Better response time
- Less complex
Conclusion:
At the end I would say, do not do a full distributed deployment simply because you can. Consider all the above points. Choosing a simple single node deployment is not so bad after all.
Another point to note, if I need to build a fully distributed environment then I would prefer using a virtual load balancer like NSX Edge, which will be much closer to the VM’s than that of a physical one kept in a traditional architecture.
I am simplifying an already complex topic and the final answer is it all depends. Every environment and requirement is different and there is no single rule to follow, but simply do not discard a simple deployment model because of the so called reasons. Consider it seriously and it may be way better for your environment than the distributed one.Till then Happy designing and let me know your view points.
Note: The above discussion is from a virtualized datacenter perspective.